14布隆过滤器BloomFilter
# 1.面试题
- 现有50亿个电话号码,现有10万个电话号码,如何要快速准确的判断这些电话号码是否已经存在
- 判断是否存在,布隆过滤器了解过吗?
- 安全连接网址,全球数10亿的网址判断
- 黑名单校验,识别垃圾邮件
- 白名单校验,识别出合法用户进行后续处理
# 2.是什么
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素
- 设计思想
- 本质就是判断具体数据是否存在于一个大的集合中
布隆过滤器是一种类似set的数据结构,只是统计结果在巨量数据下有点小瑕疵,不够完美
备注
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。
它实际上是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生

# 3.能干什么
高效地插入和查询,占用空间少,返回的结果是不确定性+不够完美。
- 减少内存占用
- 不保存数据信息,只是在内存中做一个是否存在的标记flag
# 3.1 重点
一个元素如果判断结果:存在时,元素不一定存在,但是判断结果为不存在时,则一定不存在。
布隆过滤器可以添加元素,但是**不能删除元素,**由于涉及hashcode判断依据,删掉元素会导致误判率增加。
总结
- 有,是可能有
- 无,是肯定无。可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会在集合中
# 4. 布隆过滤器原理
# 4.1 布隆过滤器实现原理和数据结构
布隆过滤器原理
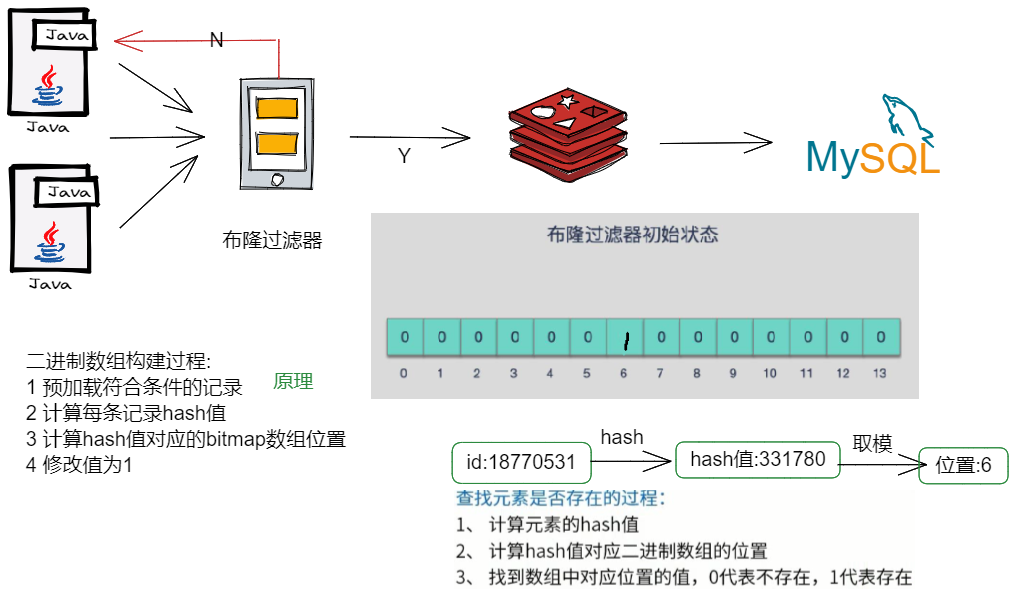
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。实质就是一个大型***位数组***和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率
添加key、查询key
添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
查询key时
只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
结论:有,是可能有,无,是肯定无
hash冲突导致数据不精准
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,把它们置为 1(假定有两个变量都通过 3 个映射函数)。
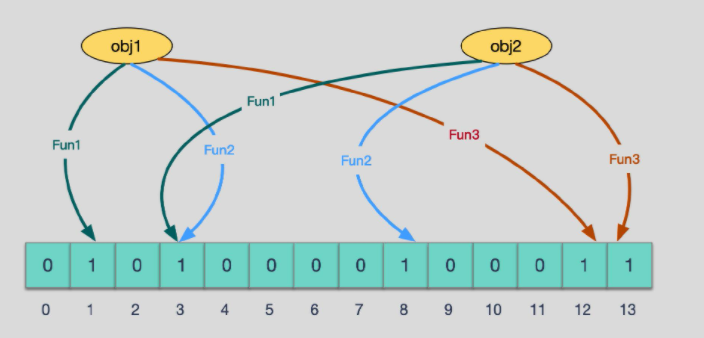
查询某个变量的时候我们只要看看这些点是不是都是 1, 就可以大概率知道集合中有没有它了,如果这些点,**有任何一个为零则被查询变量一定不在,**如果都是 1,则被查询变量很可能存在,为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。(见上图3号坑两个对象都1)

hash冲突导致数据不精准2
哈希函数
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值
如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”。
用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
Java中hash冲突java案例
public class HashCodeConflictDemo { public static void main(String[] args) { Set<Integer> hashCodeSet = new HashSet<>(); for (int i = 0; i <200000; i++) { int hashCode = new Object().hashCode(); if(hashCodeSet.contains(hashCode)) { System.out.println("出现了重复的hashcode: "+hashCode+"\t 运行到"+i); break; } hashCodeSet.add(hashCode); } System.out.println("Aa".hashCode()); System.out.println("BB".hashCode()); System.out.println("柳柴".hashCode()); System.out.println("柴柕".hashCode()); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 4.2 使用步骤
初始化bitmap
布隆过滤器 本质上 是由长度为 m 的位向量或位列表(仅包含 0 或 1 位值的列表)组成,最初所有的值均设置为 0

添加占坑位
当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash 函数对 key 进行运算,算得一个下标索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
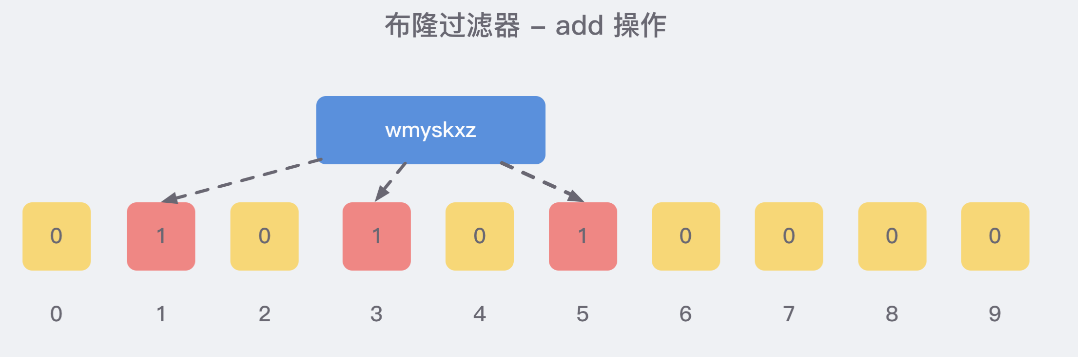
例如,我们添加一个字符串wmyskxz,对字符串进行多次hash(key) → 取模运行→ 得到坑位
判断是否存在
向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,
只要有一个位为零,那么说明布隆过滤器中这个 key 不存在;
如果这几个位置全都是 1,那么说明极有可能存在;
因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的hash冲突。。。。。
就比如我们在 add 了字符串wmyskxz数据之后,很明显下面1/3/5 这几个位置的 1 是因为第一次添加的 wmyskxz 而导致的;
此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5 ,这就是误判了......笔记见最下面
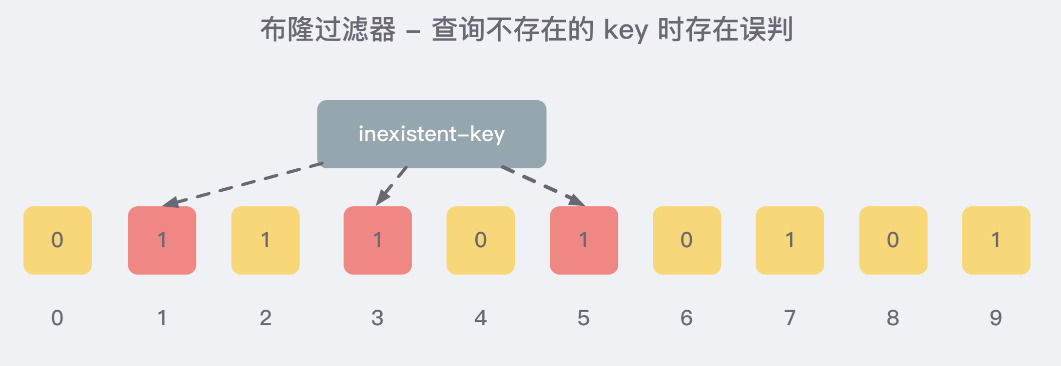
# 4.3 布隆过滤器误判率,为什么不要删除
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。
如果我们直接删除这一位的话,会影响其他的元素
特性
布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
# 4.4 总结
- 是否存在
- 有,是很可能有
- 无,是肯定无,100%无
- 使用时最好不要让实际元素数量远大于初始化数量,一次给够避免扩容
- 当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add 进行
# 5.布隆过滤器的使用场景
解决缓存穿透的问题,和redis结合bitmap使用
缓存穿透是什么
一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。
当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
缓存透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
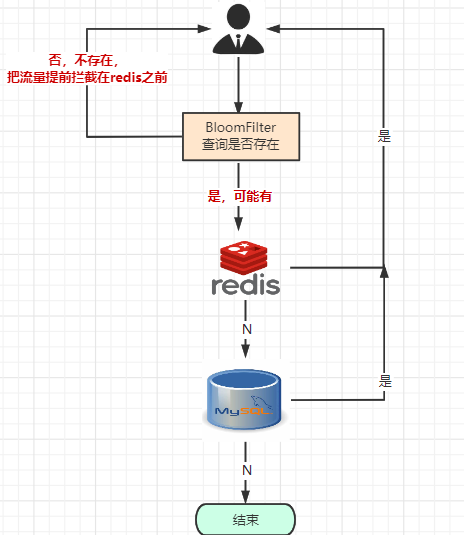
可以使用布隆过滤器解决缓存穿透的问题
把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:如果布隆过滤器中不存在该条数据则直接返回;如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则再查询Mysql数据库
黑名单校验,识别垃圾邮件
安全连接网址,全球上10亿的网址判断
# 6.尝试手写布隆过滤器,
结合bitmap类型手写一个简单的布隆过滤器,体会设计思想
# 6.1 整体架构
# 6.2 设计步骤
redis的setbit/getbit
nps2-r:db0> keys * 1) "whitelistCustomer" 2) "customer:32781" 3) "customer:20912" nps2-r:db0> type whitelistCustomer string nps2-r:db0> getbit whitelistCustomer 12 0 nps2-r:db0> getbit whitelistCustomer 1772098755 1 nps2-r:db0>1
2
3
4
5
6
7
8
9
10
11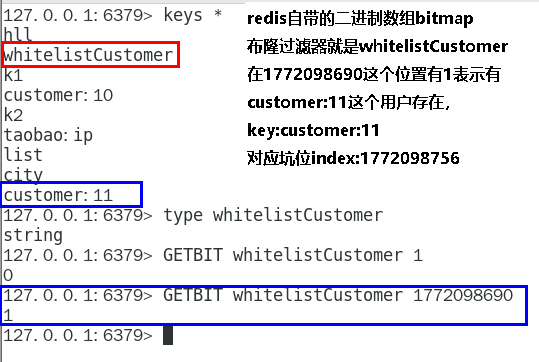
setBit的构建过程
- @PostConstruct初始化白名单数据
- 计算元素的hash值
- 通过上一步hash值算出对应的二进制数组的坑位
- 将对应坑位的值的修改为数字1,表示存在
getBit查询是否存在
- 计算元素的hash值
- 通过上一步hash值算出对应的二进制数组的坑位
- 返回对应坑位的值,零表示无,1表示存在
# 6.3关键代码
BloomFilterInit
Component
@Slf4j
public class BloomFilterInit {
@Resource
private RedisTemplate redisTemplate;
@PostConstruct//初始化白名单数据,故意差异化数据演示效果......
public void init() {
//白名单客户预加载到布隆过滤器
String uid = "customer:12";
//1 计算hashcode,由于可能有负数,直接取绝对值
int hashValue = Math.abs(uid.hashCode());
//2 通过hashValue和2的32次方取余后,获得对应的下标坑位
long index = (long) (hashValue % Math.pow(2, 32));
log.info(uid + " 对应------坑位index:{}", index);
//3 设置redis里面bitmap对应坑位,该有值设置为1
redisTemplate.opsForValue().setBit("whitelistCustomer", index, true);
}
}
// 2024-09-24T22:11:24.090+08:00 INFO 10052 --- [ main] org.clxmm.filter.BloomFilterInit : customer:12 对应------坑位index:1772098755
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
util
@Component
@Slf4j
public class CheckUtils {
@Resource
private RedisTemplate redisTemplate;
public boolean checkWithBloomFilter(String checkItem, String key) {
int hashValue = Math.abs(key.hashCode());
long index = (long) (hashValue % Math.pow(2, 32));
boolean existOK = redisTemplate.opsForValue().getBit(checkItem, index);
log.info("----->key:" + key + "\t对应坑位index:" + index + "\t是否存在:" + existOK);
return existOK;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
service
@Resource
private CheckUtils checkUtils;
public Customer findCustomerByIdWithBloomFilter(Integer customerId) {
Customer customer = null;
//缓存key的名称
String key = CACHE_KEY_CUSTOMER + customerId;
//布隆过滤器check,无是绝对无,有是可能有
//===============================================
if (!checkUtils.checkWithBloomFilter("whitelistCustomer", key)) {
log.info("白名单无此顾客信息:{}", key);
return null;
}
//===============================================
//1 查询redis
customer = (Customer) redisTemplate.opsForValue().get(key);
//redis无,进一步查询mysql
if (customer == null) {
//2 从mysql查出来customer
customer = customerMap.get(customerId);
// mysql有,redis无
if (customer != null) {
//3 把mysql捞到的数据写入redis,方便下次查询能redis命中。
redisTemplate.opsForValue().set(key, customer);
}
}
return customer;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
参数12时
2024-09-24T22:11:40.603+08:00 INFO 10052 --- [nio-8000-exec-2] org.clxmm.util.CheckUtils : ----->key:customer:12 对应坑位index:1772098755 是否存在:true
结果
- 布隆过滤器有,redis有
- 布隆过滤器有,redis无
- 布隆过滤器无,直接返回,不再继续走下去
# 7.布隆过滤器优缺点
有点
- 高效地插入和查询,内存占用bit空间少
缺点
- 不能删除元素。
- 因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的,你删除一个元素的同时可能也把其它的删除了。
- 存在误判,不能精准过滤
- 有,是很可能有
- 无,是肯定无,
100%无