03redis事务和管道
# redis事务
# 1.是什么
可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞
# 2.能干什么
一个队列中,一次性、顺序性、排他性的执行一系列命令
# 3.Redis事务 VS 数据库事务
| 1 单独的隔离操作 | Redis的事务仅仅是保证事务里的操作会被连续独占的执行,redis命令执行是单线程架构,在执行完事务内所有指令前是不可能再去同时执行其他客户端的请求的 |
|---|---|
| 2 没有隔离级别的概念 | 因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”这种问题了 |
| 3不保证原子性 | 不保证原子性,也就是不保证所有指令同时成功或同时失败,只有决定是否开始执行全部指令的能力,没有执行到一半进行回滚的能力 |
| 4 排它性 | Redis会保证一个事务内的命令依次执行,而不会被其它命令插入 |
# 4.如何使用
常用命令
Redis 事务 | 菜鸟教程 (runoob.com) (opens new window)
常见操作
case1:正常执行
127.0.0.1:6379> MULTI OK 127.0.0.1:6379(TX)> set k1 v1 QUEUED 127.0.0.1:6379(TX)> set k2 v2 QUEUED 127.0.0.1:6379(TX)> set k3 v3 QUEUED 127.0.0.1:6379(TX)> INCR count QUEUED 127.0.0.1:6379(TX)> EXEC 1) OK 2) OK 3) OK 4) (integer) 1 127.0.0.1:6379> get k3 "v3"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17case2:放弃执行
127.0.0.1:6379> MULTI OK 127.0.0.1:6379(TX)> set k3 v3 QUEUED 127.0.0.1:6379(TX)> INCR count QUEUED 127.0.0.1:6379(TX)> DISCARD OK 127.0.0.1:6379> get k3 "v3" 127.0.0.1:6379> get count "1"1
2
3
4
5
6
7
8
9
10
11
12case3: 全体连坐-全部失败
127.0.0.1:6379> MULTI OK 127.0.0.1:6379(TX)> set k2 v2 QUEUED 127.0.0.1:6379(TX)> set k2 v2 QUEUED 127.0.0.1:6379(TX)> set k3 (error) ERR wrong number of arguments for 'set' command 127.0.0.1:6379(TX)> EXEC (error) EXECABORT Transaction discarded because of previous errors.1
2
3
4
5
6
7
8
9
10case4:冤头债主-成功的成功,失败的失败
127.0.0.1:6379> set email 123@qq.com OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379(TX)> set k1 v1 QUEUED 127.0.0.1:6379(TX)> INCR email QUEUED 127.0.0.1:6379(TX)> INCR count QUEUED 127.0.0.1:6379(TX)> EXEC 1) OK 2) (error) ERR value is not an integer or out of range 3) (integer) 11
2
3
4
5
6
7
8
9
10
11
12
13
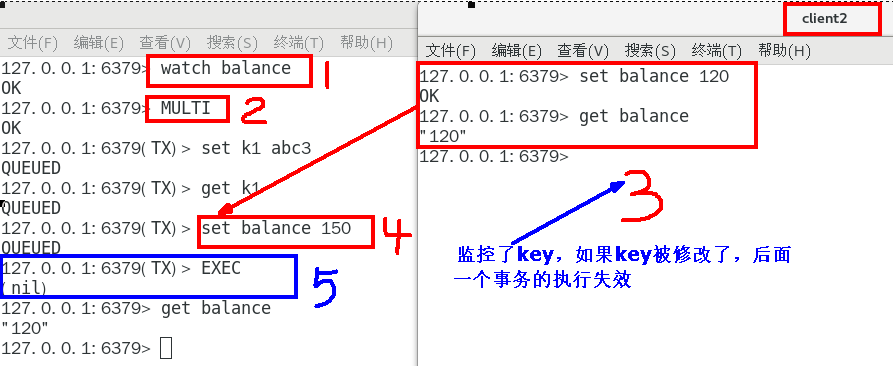
14case5:watch监控
Redis使用Watch来提供乐观锁定,类似于CAS(Check-and-Set)
- 悲观锁: 悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。
- 乐观锁: 乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。乐观锁策略:提交版本必须 大于 记录当前版本才能执行更新
- CAS:
watch:
正常情况下:初始化k1和balance两个key,先监控再开启multi,保证两key变动在同一个事务内
127.0.0.1:6379> set k1 abc OK 127.0.0.1:6379> set balance 100 OK 127.0.0.1:6379> WATCH balance OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379(TX)> set k1 abc2 QUEUED 127.0.0.1:6379(TX)> set balance 110 QUEUED 127.0.0.1:6379(TX)> EXEC 1) OK 2) OK 127.0.0.1:6379> get k1 "abc2" 127.0.0.1:6379> get balance "110"1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19监控的数据被修改:
watch命令是一种乐观锁的实现,Redis在修改的时候会检测数据是否被更改,如果更改了,则执行失败
第一个窗口蓝色框第5步执行结果返回为空,也就是相当于是失败,笔记见最下面官网说明
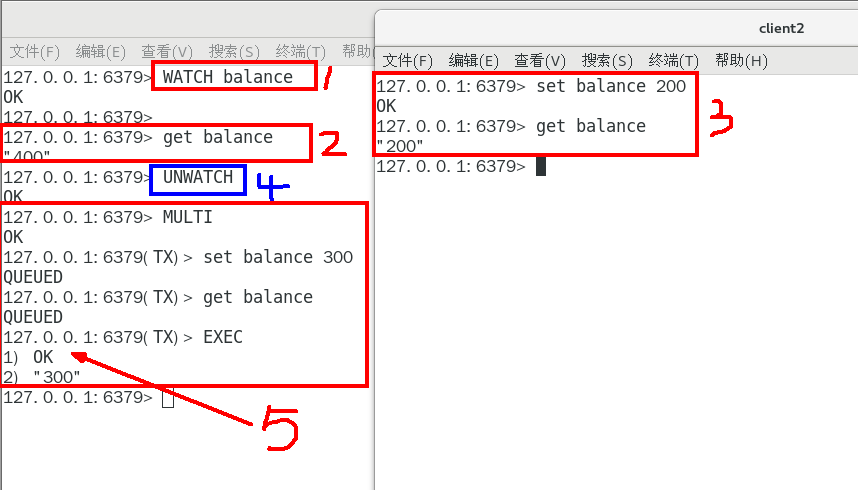
unwatch:
# 5. 总结
- 开启:以MULTI开始一个事务
- 入队:将多个命令入队到事务中,接到这些命令并不会立即执行,
- 执行:由EXEC命令触发事务
# redis 管道
# 问题
如何优化频繁命令往返造成的性能瓶颈?
问题由来
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。一个请求会遵循以下步骤:
- 1 客户端向服务端发送命令分四步(发送命令→命令排队→命令执行→返回结果),并监听Socket返回,通常以阻塞模式等待服务端响应。
- 2 服务端处理命令,并将结果返回给客户端。
上述两步称为:Round Trip Time(简称RTT,数据包往返于两端的时间),问题笔记最下方
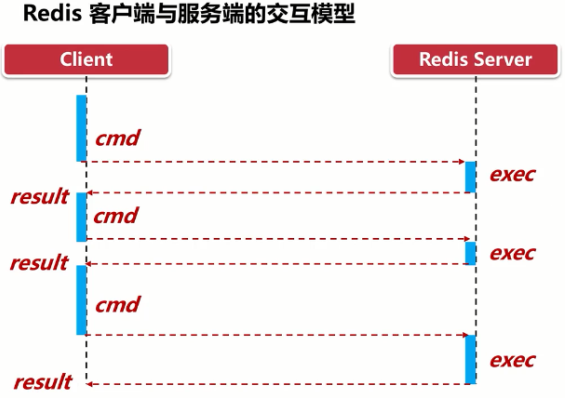
如果同时需要执行大量的命令,那么就要等待上一条命令应答后再执行,这中间不仅仅多了RTT(Round Time Trip),而且还频繁调用系统IO,发送网络请求,同时需要redis调用多次read()和write()系统方法,系统方法会将数据从用户态转移到内核态,这样就会对进程上下文有比较大的影响了,性能不太好,o(╥﹏╥)o
# 1.定义
管道(pipeline)可以一次性发送多条命令给服务端,服务端依次处理完完毕后,通过一条响应一次性将结果返回,通过减少客户端与redis的通信次数来实现降低往返延时时间。pipeline实现的原理是队列,先进先出特性就保证数据的顺序性。
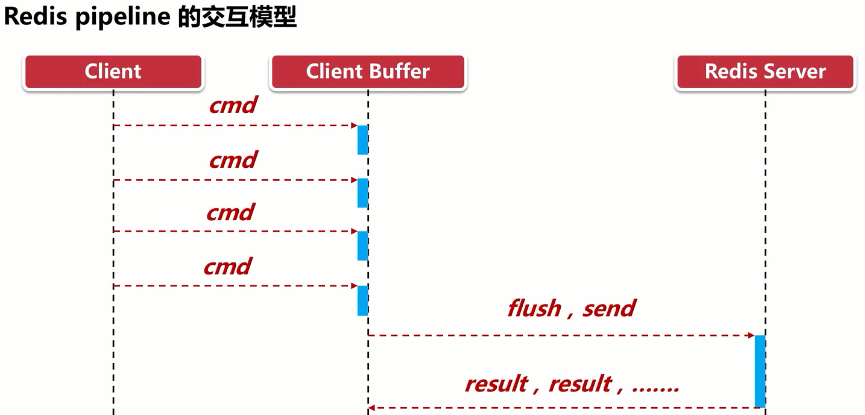
Pipeline是为了解决RTT往返回时,仅仅是将命令打包一次性发送,对整个Redis的执行不造成其它任何影响
批处理命令变种优化措施,,类似Redis的原生批命令(mget和mset)
# 2.演示
[root@localhost redis-7.0.0]# cat cmd.txt
set k1 v100
set k2 v200
hset k3 name zs
hset k3 age 18
lpush liset1 1 2 3
[root@localhost redis-7.0.0]# cat cmd.txt | ./src/redis-cli -a 123456abc --pip
Unrecognized option or bad number of args for: '--pip'
[root@localhost redis-7.0.0]# cat cmd.txt | ./src/redis-cli -a 123456abc --pipe
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 5
2
3
4
5
6
7
8
9
10
11
12
13
14
# 3.总结
- Pipeline与原生批量命令对比
- 原生批量命令是原子性(例如:mset, mget),pipeline是非原子性
- 原生批量命令一次只能执行一种命令,pipeline支持批量执行不同命令
- 原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
- Pipeline与事务对比
- 事务具有原子性,管道不具有原子性
- 管道一次性将多条命令发送到服务器,事务是一条一条的发,事务只有在接收到exec命令后才会执行,管道不会
- 执行事务时会阻塞其他命令的执行,而执行管道中的命令时不会
- 使用Pipeline注意事项
- pipeline缓冲的指令只是会依次执行,不保证原子性,如果执行中指令发生异常,将会继续执行后续的指令
- 使用pipeline组装的命令个数不能太多,不然数据量过大客户端阻塞的时间可能过久,同时服务端此时也被迫回复一个队列答复,占用很多内存